
2024 "AI Image Generation" Project Collection
With just a
simple prompt, a little patience, and a burst of
imagination, one can transform ideas into vivid, lifelike artwork.
Image generation, as an AIGC application driven by AI large models, is disrupting
traditional content creation and art design, allowing everyone to become a "master painter."
With just a simple prompt, a little patience, and a series of wild ideas, one can transform them into vivid
and lifelike artworks. As 2024 draws to a close, the field of "AI image generation" has seen numerous
outstanding research achievements, greatly enriching the ecosystem of image content creation. These come
from leading tech giants, university labs, and individual developers, with some research already being
open-sourced.
In this summary article, we focus on sharing "research-oriented" AI image generation projects. We have
selected 18 out of 100 projects to share with you (listed in chronological order of release, see the
original text at the end).
1. InstantID: Second-level zero-shot high-fidelity image generation
In the field of personalized image synthesis, methods like Textual Inversion, DreamBooth, and LoRA have made significant progress. However, the practical application of these methods is limited by high storage requirements, lengthy fine-tuning processes, and the need for multiple reference images. In contrast, existing ID embedding-based methods, while requiring only a single forward inference, also face challenges: either they require extensive fine-tuning of numerous model parameters, are incompatible with community-pretrained models, or fail to maintain high facial realism. To address these limitations, the research teams from InstantX and Xiaohongshu proposed a diffusion model-based solution, InstantID. Its plug-and-play module cleverly handles image personalization across various styles using just a single facial image while ensuring high fidelity. To achieve this, the researchers designed IdentityNet, which combines strong semantic and weak spatial conditions to merge facial and landmark images with text prompts to guide image generation.

InstantID demonstrates excellent performance and efficiency, making it highly
valuable for practical applications that require maintaining identity authenticity. Moreover, InstantID can
serve as an adaptable plugin, seamlessly integrating with popular pre-trained text-to-image diffusion
models, such as SD 1.5 and SDXL.
Paper link: https://arxiv.org/abs/2401.07519
Project link:
https://instantid.github.io/
2. PhotoMaker: Efficient Personalized Custom Portrait Photography
In recent years, text-to-image technology has made significant progress in
synthesizing realistic human photos based on given text prompts. However, existing personalized generation
methods fail to meet the requirements of high efficiency, maintaining identity (ID) fidelity, and flexible
text controllability simultaneously.
To address this, research teams from Nankai University, Tencent, and the University of Tokyo proposed an
efficient personalized text-to-image generation method—
PhotoMaker. PhotoMaker is capable of encoding any number of input ID images into a stacked ID embedding to
retain ID information. As a unified ID representation, this embedding not only comprehensively encapsulates
the features of the same input ID but also accommodates features of different IDs for subsequent
integration. This opens up possibilities for more interesting and practically valuable applications.
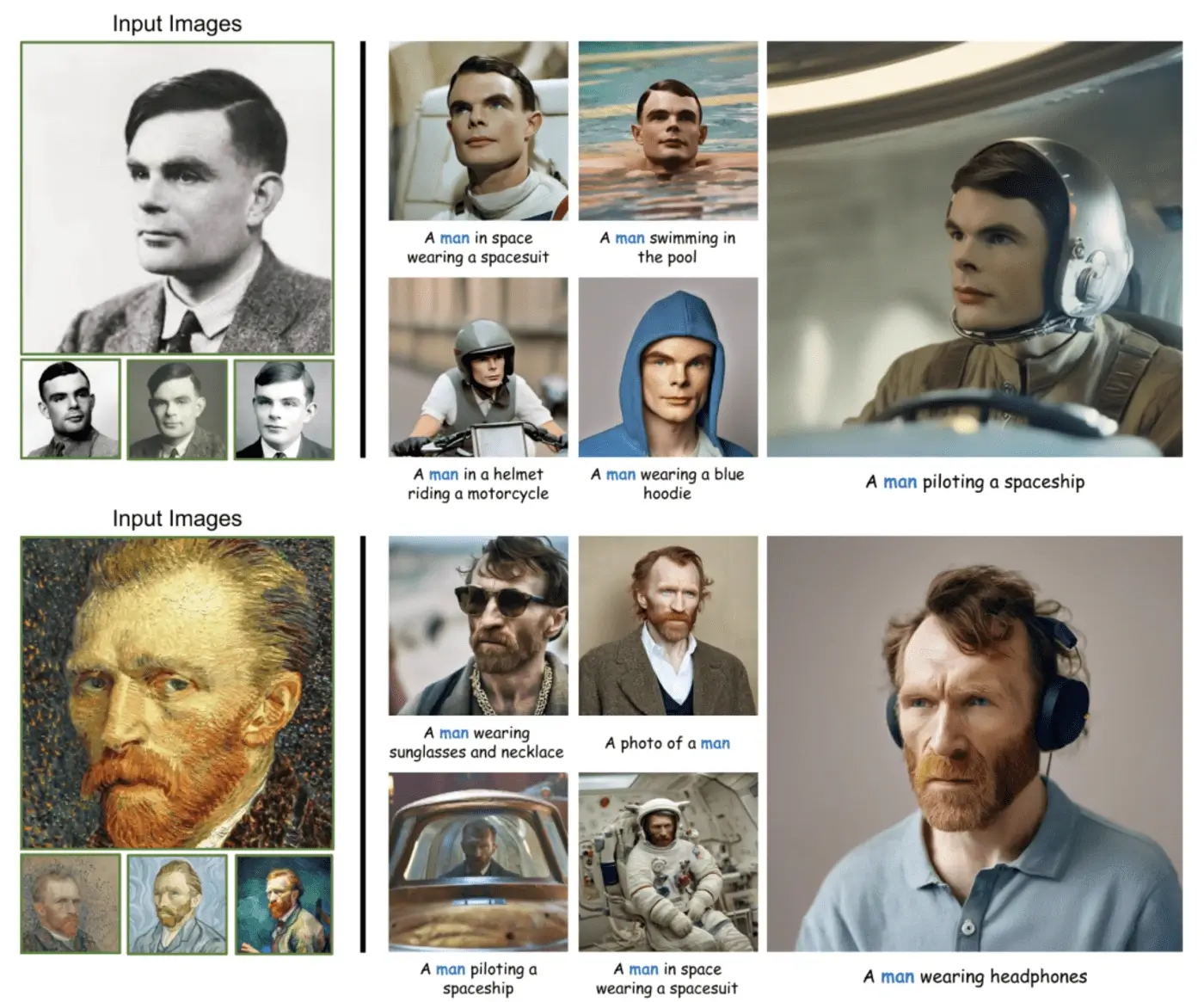
In order to promote the training of PhotoMaker, the researchers proposed an
ID-oriented data construction pipeline to collect training data. Compared to methods based on test-time
fine-tuning, under the nourishment of the dataset constructed by this method, PhotoMaker demonstrates better
ID preservation capabilities, along with significant speed improvements, high-quality generated results,
strong generalization ability, and a wide range of applications.
Paper link: https://arxiv.org/abs/2312.04461
Project link:
https://photo-maker.github.io/
3. ConsiStory: Consistent Text - to - Image Generation without Extra Training
Text - to - image models allow users to guide the image - generation process
through natural language, elevating creative flexibility to a new level. However, it remains challenging to
consistently depict the same subject across different prompts when using these models. Existing methods
teach the model new words for specific subjects provided by users by fine - tuning the model, or add image
conditions to the model. These methods require long - term optimization for each subject or large - scale
pre - training. Meanwhile, it is difficult to align the generated images with text prompts, and there are
also difficulties in describing multiple subjects.
To this end, a research team from NVIDIA and Tel Aviv University, along with their collaborators, proposed a
training - free method called ConsiStory. It achieves consistent subject generation by sharing the internal
activations of pre - trained models.

The research team introduced topic - driven shared attention blocks and
correspondence - based feature injection to promote topic consistency among images. To encourage layout
diversity while maintaining topic consistency, the research team compared ConsiStory with a series of
baselines. Without any optimization steps, ConsiStory achieved state - of - the - art (SOTA) performance in
terms of topic consistency and text alignment. ConsiStory can naturally scale to multi - topic scenarios and
even enable training - free personalization of common objects.
Paper link: https://arxiv.org/abs/2402.03286
Project link: https://research.nvidia.com/labs
/par/consistory/
4. Just one picture is needed to customize personalized photos easily and quickly.
A research team from the University of Hong Kong, Alibaba, and Ant Group has introduced a practical tool, FlashFace. Users can easily and instantly personalize their photos just by providing one or several reference face images and text prompts.

FlashFace is different from existing human photo customization methods, boasting
higher identity fidelity and better instruction - following capabilities, thanks to two subtle designs.
First, this technology encodes the face identity as a series of feature maps, rather than encoding it as an
image token as in previous technologies. This enables the model to retain more details of the reference
face, such as scars, tattoos, and facial shapes. Second, during the text - to - image generation process,
FlashFace introduces a separation - integration strategy to balance text and image guidance, thus
alleviating the conflict between the reference face and the text prompt (for example, personalizing an adult
into a "child" or an "elderly person").
Numerous experiments have demonstrated the effectiveness of FlashFace in various applications,
including portrait personalization, face swapping under language prompts, and turning virtual characters
into real - life - like people.
Paper link: https://arxiv.org/abs/2403.17008
Project link: https://jshilong.github.io/flashface-page/
5. Huawei proposed PixArt - Σ: Directly generate 4K - resolution images
A research team from Huawei Noah's Ark Lab, Dalian University of Technology, the University of Hong Kong, and the Hong Kong University of Science and Technology has proposed a Diffusion Transformer (DiT) named PixArt - Σ that can directly generate 4K - resolution images. Compared with its predecessor PixArt - α, PixArt - Σ has made significant progress, with a notable improvement in image fidelity and better alignment with text prompts.

One of the main features of PixArt - Σ is its training efficiency. Leveraging the
basic pre - training of PixArt - α, it evolves from a "weak" baseline to a "strong" model by incorporating
higher - quality data, which we call the "weak - to - strong training" process. The progress of PixArt - Σ
is reflected in two aspects: First, high - quality training data: PixArt - Σ integrates higher - quality
image data, along with more accurate and detailed image descriptions. Second, efficient token compression.
The research team proposed a new attention module within the DiT framework that can compress both keys and
values simultaneously, thus significantly improving efficiency and facilitating the generation of ultra -
high - resolution images.
Thanks to these improvements, PixArt - Σ achieves excellent image quality and user - prompt
functionality. Meanwhile, its model size (0.6B parameters) is significantly smaller than existing text - to
- image diffusion models such as SDXL (2.6B parameters) and SD Cascade (5.1B parameters). In addition,
PixArt - Σ can generate 4K images, supporting the production of high - resolution posters and wallpapers,
and effectively facilitating the production of high - quality visual content in industries such as film and
games.
Paper link: https://arxiv.org/abs/2403.04692
Project link: https://pixart-alpha.github.io/PixArt-sigma-project/
6. CogView3:Achieving More Precise and Faster "Text - to - Image" through Relay Diffusion
The latest advancements in text - to - image systems have been primarily driven by
diffusion models. However, single - stage text - to - image diffusion models still face challenges in
computational efficiency and image detail refinement. To address this issue, a research team from Tsinghua
University and AI Era proposed CogView3, an innovative cascading framework that can enhance the performance
of text - to - image diffusion.
It is reported that CogView3 is the first model to implement relay diffusion in the field of text - to
- image generation. It performs tasks by first creating low - resolution images and then applying relay -
based super - resolution. This approach not only produces competitive text - to - image outputs but also
significantly reduces training and inference costs.

Experimental results show that in human evaluations, CogView3 outperforms the
current state - of - the - art open - source text - to - image diffusion model SDXL by 77.0%, while
requiring only half of the inference time of the latter. The distilled variant of CogView3 has performance
comparable to SDXL, but with an inference time that is only one - tenth of that of SDXL.
Paper link: https://arxiv.org/abs/2403.05121
Github link:
https://github.com/THUDM/
CogView3
7. SPRIGHT: Improving Spatial Consistency in Text - to - Image Models
One of the major drawbacks of current text - to - image (T2I) models is their
inability to consistently generate images that are faithful to the spatial relationships specified in the
text prompts. A research team from Arizona State University, Intel Labs, and their collaborators conducted a
comprehensive study of this limitation. They also developed a dataset and methods that achieve SOTA.
The inability to consistently generate images that are faithful to the spatial relationships specified in
text prompts is one of the primary flaws of current text - to - image (T2I) models. A research team from
Arizona State University, Intel Labs, and their collaborators conducted a comprehensive study of this
limitation. Meanwhile, they developed a dataset and methods that achieve state - of - the - art (SOTA)
performance.

In addition, they found that training on images containing a large number of
objects can significantly improve spatial consistency. Notably, by fine - tuning on fewer than 500 images,
they achieved state - of - the - art (SOTA) performance on T2I - CompBench, with a spatial score of 0.2133.
Paper link: https://arxiv.org/abs/2404.01197
Project link:
https://spright-t2i.github.io/
8. RLCM: Fine - tuning Consistency Models via Reinforcement Learning
Reinforcement learning (RL) improves the guided image generation of diffusion
models by directly optimizing to obtain rewards for image quality, aesthetics, and instruction - following
capabilities. However, the resulting generation strategy inherits the iterative sampling process of
diffusion models, leading to slow generation speed. To overcome this limitation, consistency models propose
learning a new class of generative models that directly map noise to data, resulting in a model that can
generate images with only one sampling iteration.
In this work, to optimize text - to - image generation models for specific task rewards and achieve fast
training and inference, a research team from Cornell University proposed a framework for fine - tuning
consistency models via RL.
RLCM, which formulates the iterative inference process of the consistency model as an RL process. RLCM
improves the RL - fine - tuned diffusion models in terms of text - to - image generation capabilities, and
trades computational cost for sample quality during the inference process.

Experiments show that RLCM can adjust text - to - image consistency models to adapt
to goals that are difficult to express through prompts (such as image compressibility) and those from human
feedback (such as aesthetic quality). Compared with RL - fine - tuned diffusion models, RLCM trains
significantly faster, improves the generation quality measured under reward goals, and speeds up the
inference process, being able to generate high - quality images with just two inference steps.
Paper link: https://arxiv.org/abs/2404.03673
Project link:
hhttps://rlcm.owenoertell.com/
9. Tsinghua University and Meta Propose a New Method for Customized Text - to - Image Generation: MultiBooth
A research team from Tsinghua University and Meta has proposed a new and efficient technique for multi - concept customization in text - to - image generation, called MultiBooth. Despite significant progress in customized generation methods, especially with the rapid development of diffusion models, existing methods still struggle with multi - concept scenarios due to low concept fidelity and high inference costs.
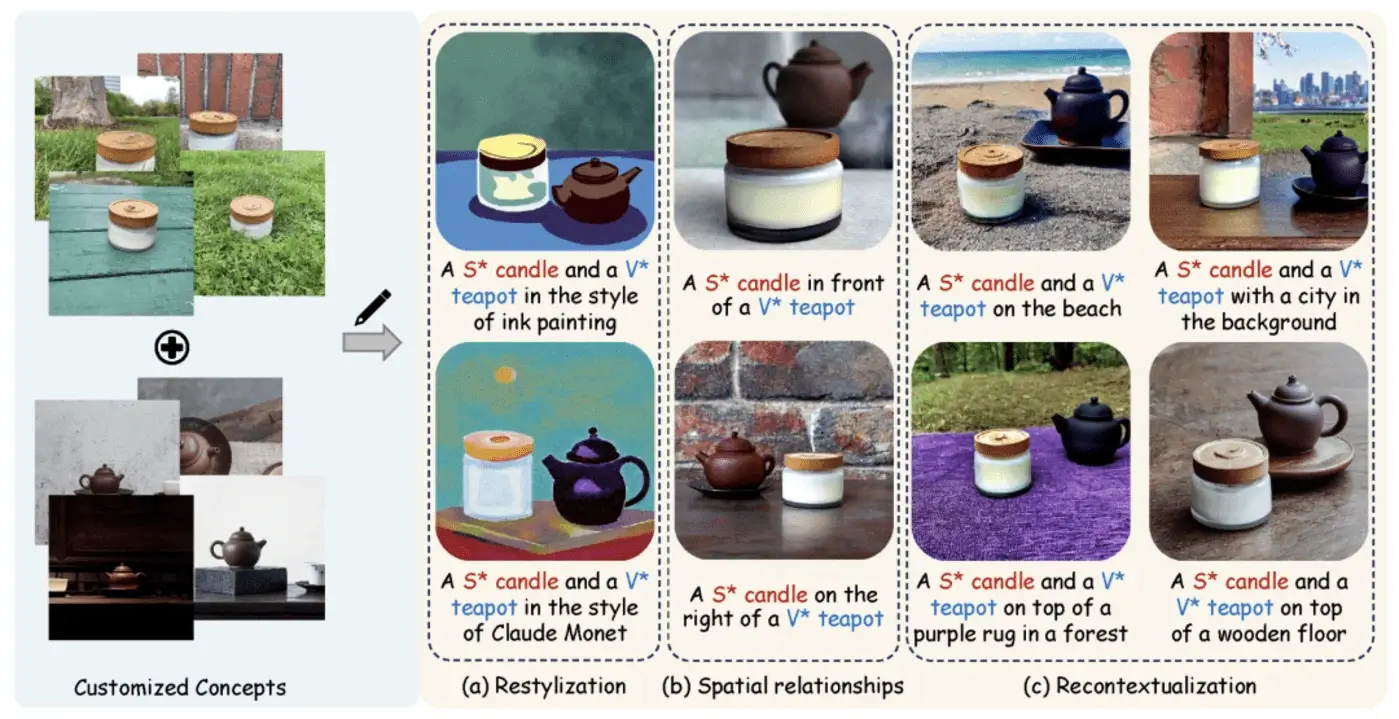
To address these issues, MultiBooth divides the multi - concept generation process
into two stages: the single - concept learning stage and the multi - concept integration stage. In the
single - concept learning stage, they adopt a multi - modal image encoder and an efficient concept encoding
technique to learn a concise and discriminative representation for each concept. In the multi - concept
integration stage, they use bounding boxes to define the generation area of each concept in the cross -
attention map. This approach enables the creation of single concepts within the specified areas, thus
facilitating the formation of multi - concept images.
This strategy not only improves the concept fidelity but also reduces the additional inference costs. In
both qualitative and quantitative evaluations, MultiBooth outperforms various baselines, demonstrating its
superior performance and computational efficiency.
Paper link: https://arxiv.org/abs/2404.14239
Project link:
https://multibooth.github.io/
10. Teams from Tsinghua University and AI Era Launch the Infinite Super - Resolution Model Inf - DiT
In recent years, diffusion models have demonstrated excellent performance in image
generation. However, due to the quadratic increase in memory during the generation of ultra - high -
resolution images (such as 4096×4096), the resolution of generated images is often limited to 1024×1024.
In this work, a research team from Tsinghua University and AI Era proposed a unidirectional block attention
mechanism. This mechanism can adaptively adjust the memory overhead during the inference process and handle
global dependencies. Based on this module, they adopted the DiT architecture for upsampling and developed an
infinite super - resolution model capable of upsampling images of various shapes and resolutions.

Comprehensive experiments show that this model achieves state - of - the - art
(SOTA) performance in both machine and human evaluations for generating ultra - high - resolution images.
Compared with the commonly used UNet architecture, this model can save more than five times the memory when
generating 4096×4096 images.
Paper link: https://arxiv.org/abs/2405.04312
ttps://arxiv.org/abs/2410.10629 https://github.com/THUDM/Inf-DiT
11. A New Work by Kai - ming He: Autoregressive Image Generation without Vector Quantization
The traditional view holds that autoregressive models for image generation are
usually accompanied by vector - quantized tokens.
The team led by Kai Ming He from the MIT Computer Science and Artificial Intelligence Laboratory (MIT
CSAIL), along with collaborators from Google DeepMind and Tsinghua University, have discovered that while a
discrete - valued space is helpful for representing categorical distributions, it is not a necessary
condition for autoregressive modeling.
In this work, they proposed using a diffusion process to model the probability distribution of each token,
enabling the application of autoregressive models in a continuous - valued space. Instead of using
categorical cross - entropy loss, they defined a diffusion loss function to model the probability of each
token. This approach eliminates the need for discrete - valued tokenizers. They evaluated its effectiveness
in various scenarios, including standard autoregressive models and generalized masked autoregressive (MAR)
variants. By removing vector quantization, the image generator they proposed not only enjoys the speed
advantage of sequence modeling but also achieves excellent results.

They hope that this work will promote the application of autoregressive generation
techniques in other continuous - valued fields and applications.
Paper link: https://arxiv.org/abs/2406.11838
Github link:
https://github.com/LTH14/mar
12. Xiaohongshu Launches StoryMaker: Achieving Overall Feature Consistency in "Text - to - Image" Generation
Tuning - free personalized image generation methods have achieved great success in
maintaining facial consistency. However, in scenes with multiple characters, the lack of overall consistency
hinders the ability of these methods to create coherent narratives. In this work, the Xiaohongshu team
introduced a personalized solution -
StoryMaker can maintain not only the consistency of facial features but also that of clothing, hairstyles,
and body figures, thus facilitating the creation of stories through a series of images.

StoryMaker, which can maintain not only facial consistency but also consistency in
clothing, hairstyles, and body, thus facilitating the creation of stories through a series of images.
Paper link: https://arxiv.org/abs/2409.12576
Github link:
https://github.com/RedAIGC/
StoryMaker
13. NVIDIA's Text - to - Image Framework SANA: Efficiently Generate High - Resolution Images
The research team of NVIDIA and its collaborators have proposed a text - to - image framework, Sana, which can efficiently generate images with a resolution of up to 4096×4096. Sana can synthesize high - resolution and high - quality images at an extremely fast speed on a laptop GPU, and it has a strong ability to align text with the generated images.

The core designs include:
(1) Deep Compression Auto - encoder: Unlike traditional auto - encoders that can only compress images 8 -
fold, the auto - encoder they trained can compress images 32 - fold, effectively reducing the number of
latent tokens.
(2) Linear DiT: They replaced all vanilla attention in DiT with linear attention. Linear attention is more
efficient at high resolutions without sacrificing quality.
(3) Pure - decoder Text Encoder: They replaced T5 with a modern small - scale pure - decoder large -
language model (LLM) as the text encoder, and designed sophisticated human - machine instructions and
learning from context to enhance the alignment between images and text.
(4) Efficient Training and Sampling: They proposed Flow - DPM - Solver to reduce the number of sampling
steps, and accelerated convergence through efficient caption annotation and selection.
Compared with modern giant diffusion models such as Flux - 12B, Sana - 0.6B is highly competitive. It is 20
times smaller in size and over 100 times faster in measured throughput. In addition, Sana - 0.6B can be
deployed on a 16GB laptop GPU and takes less than 1 second to generate an image with a resolution of
1024×1024. Sana enables content creation at a low cost.
Paper link: https://arxiv.org/abs/2410.10629
Project link:
https://nvlabs.github.io/Sana/
14. Kandinsky - 3: A New Type of Text - to - Image Diffusion Model
Text - to - Image (T2I) diffusion models are commonly used models for introducing image processing methods, such as editing, image blending, inpainting, etc. Meanwhile, Image - to - Video (I2V) and Text - to - Video (T2V) models are also built on T2I models. A research team from SberAI and its collaborators have introduced a new T2I model based on latent diffusion - Kandinsky 3, which features high quality and realism.

The main features of the new architecture are simplicity and high efficiency,
enabling it to adapt to various types of generation tasks. They extended the basic T2I model for a wide
range of applications and created a versatile generation system, which includes text - guided
inpainting/outpainting, image blending, text - image fusion, image variation generation, I2V, and T2V
generation. They also proposed a refined version of the T2I model. Without sacrificing image quality, this
refined model evaluates inference in 4 steps of the reverse process and is 3 times faster than the basic
model. They have deployed a user - friendly demonstration system, and all functions can be tested in the
public domain.
In addition, they have released the source code and checkpoints of Kandinsky 3 and the extended models. The
results of human evaluation show that Kandinsky 3 is one of the open - source generation systems with the
highest quality scores.
Paper link: https://arxiv.org/abs/2410.21061
Github link: https://github.com/ai-forever/Kandinsky-3
15. FlipSketch: Transforming Static Drawings into Text - guided Sketch Animations
Sketch animation provides a powerful medium for visual storytelling, encompassing
everything from simple flip - book doodles to professional studio productions. Traditional animation
production requires a team of skilled artists to draw keyframes and in - betweens. Existing attempts at
automation still demand a significant amount of artistic work through precise motion path or keyframe
specifications.
In this work, the SketchX team from the University of Surrey introduced the FlipSketch system, which allows
you to rediscover the charm of flip - book animation — all you need to do is draw your ideas and describe
how you want them to move.
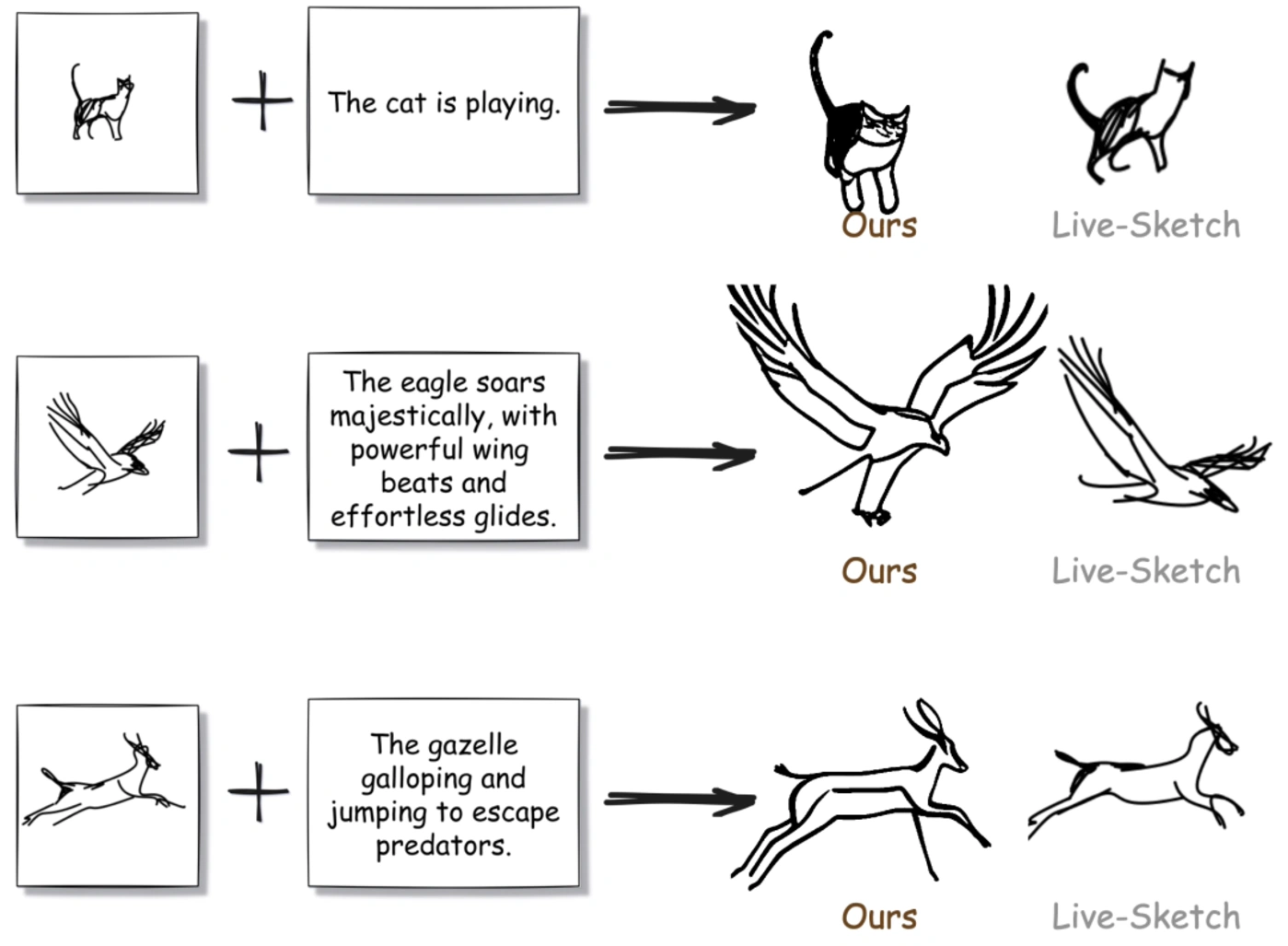
This approach leverages the motion priors from text - to - video diffusion models
and adapts them to generate sketch animations through three key innovations: (1) fine - tuning the frame
generation in a sketch style, (2) a reference - frame mechanism that maintains the visual integrity of the
input sketches through noise refinement, (3) dual - attention synthesis to achieve smooth motion without
losing visual consistency. Unlike restricted vector animations, their raster - based framework supports
dynamic sketch transformations, capturing the free - form expressiveness of traditional animations.
Paper link: https://arxiv.org/abs/2411.10818
Project link: https://hmrishavbandy.github.io/
flipsketch-web/
16. OneDiffusion: One Diffusion to Generate All
In this work, a research team from AI2 and the University of California, Irvine introduced a general - purpose large - scale diffusion model, OneDiffusion. It can seamlessly support two - way image synthesis and understanding in different tasks. It can generate images based on inputs such as text, depth, pose, layout, and semantic maps. At the same time, it can also handle reverse - processing tasks such as image de - blurring, upscaling, as well as depth estimation and segmentation.

In addition, OneDiffusion can generate multi - views, perform camera pose
estimation, and utilize continuous image inputs for instant personalization. During the training process,
the model treats all tasks as frame sequences with different noise scales, allowing any frame to serve as a
conditional image during inference. This unified training framework does not require a dedicated
architecture, supports scalable multi - task training, and can adapt to any resolution, thus enhancing
generality and scalability.
Experimental results show that, despite a relatively small training dataset, this training framework is
highly competitive in generation and prediction tasks such as text - to - image, multi - view generation,
identity protection, depth estimation, and camera pose estimation.
Paper link: https://arxiv.org/abs/2411.16318
Github link: https://github.com/lehduong/
OneDiffusion
17. The team from Peking University proposed the "Custom Comic Generation" framework DiffSensei
Story visualization is the task of creating visual narratives from textual
descriptions, and progress has been made in text - to - image generation models. However, these models often
lack effective control over the appearance and interactions of characters, especially in multi - character
scenarios.
To address these limitations, a research team from Peking University and their collaborators proposed a new
task: custom comic generation, and introduced DiffSensei, an innovative framework specifically designed for
generating dynamic multi - character - controlled comics. DiffSensei integrates a diffusion - based image
generator and a multi - modal large language model (MLLM), with the latter serving as a text - compatible
identity adapter. Their approach employs masked cross - attention technology to seamlessly integrate
character features, enabling precise layout control without directly transferring pixels. Additionally, the
MLLM - based adapter can adjust character features to align with the text cues of specific panels, thus
flexibly adjusting the characters' expressions, poses, and actions.

They also introduced MangaZero, a large - scale dataset specifically tailored for
this task. It contains 43,264 comic pages and 427,147 annotated panels, supporting the visualization of
various character interactions and actions across consecutive frames. Extensive experiments have
demonstrated that DiffSensei outperforms existing models. By enabling text - adaptable character
customization, it marks a significant advancement in comic - generation technology.
Paper link: https://arxiv.org/abs/2412.07589
Project link: https://jianzongwu.github.io/
projects/diffsensei/
18. SnapGen: Tiny, Fast High - Resolution "Text - to - Image"
Existing Text - to - Image (T2I) diffusion models face several limitations, including large model size, slow operation speed, and low - quality images generated on mobile devices. The research team from Snap and its collaborators aim to address all these challenges by developing an extremely small and fast T2I model that can generate high - resolution and high - quality images on mobile platforms.

To achieve this goal, they proposed several techniques. First, they systematically
examined the design choices of the network architecture to reduce model parameters and latency while
ensuring high - quality generation. Second, to further improve the generation quality, they adopted cross -
architecture knowledge distillation from a larger model, using a multi - level approach to guide the
training of their model from scratch. Third, they achieved generation in just a few steps by combining
adversarial guidance with knowledge distillation.
Their model, SnapGen, only takes 1.4 seconds to generate a 1024x1024 px image on mobile devices. On
ImageNet - 1K, the model can generate 256x256 px images with only 372M parameters, achieving an FID of 2.06.
On T2I benchmarks (i.e., GenEval and DPG - Bench), their model, with just 379M parameters, outperforms large
models with billions of parameters at a significantly smaller scale (for example, 7 times smaller than SDXL
and 14 times smaller than IF - XL).
Paper link: https://arxiv.org/abs/2412.09619
Project link: https://snap-research.github.io/snapgen/
Full version:
https://oosdj1g7qa.feishu.cn/docx/
YXfLdKN6po7UPsxC3Eycoboondg
