
图像生成、作为由人工智能(AI)大模型驱动的 AIGC 应用方向、正在颠覆传统的内容创作和艺术设计、让人人都可以成为「绘画大师」——
只需要一段简单的 prompt、加上一点点耐心、一个个天马行空的想法、就可以化为一幅幅栩栩如生的画作。
在即将结束的 2024 年、「AI 图像生成」领域涌现出了众多优秀的研究成果、大大丰富了图像内容创作的生态、这些成果来自头部科技大厂、高校院所实验室和个人开发者、部分研究也已开源。
在这篇总结文章中、我们专注于分享那些「研究类」AI 图像生成项目、我们挑选了 100 个项目中的 18 个分享给大家。(按照发布时间先后顺序、原文见文末。)
1.InstantID:秒级零样本保真图像生成
在个性化图像合成方面、诸如 Textual Inversion、DreamBooth 和 LoRA 等方法已经取得了重大进展。然而、这些方法的实际应用受到了高存储需求、漫长的微调过程以及需要多张参考图像的限制。相比之下、现有的基于 ID 嵌入的方法虽然只需一次前向推理、但也面临挑战:要么需要对大量模型参数进行广泛的微调、要么与社区预训练模型不兼容、要么无法保持高面部真实性。 为了解决这些限制、来自 InstantX 和小红书的研究团队提出了一个基于扩散模型的解决方案 InstantID、其即插即用模块仅使用单张面部图像就巧妙地处理各种风格的图像个性化、同时确保高保真度。为了实现这一点、研究人员设计了一个 IdentityNet、通过强语义和弱空间条件的结合、将面部图像和地标图像与文本提示相结合、引导图像生成。

InstantID 展示了优异的性能和效率、在需要保持身份真实性的实际应用中非常有价值。此外、InstantID
可以作为一个可适配的插件、能够与流行的预训练文本到图像扩散模型(如 SD 1.5 和 SDXL)无缝集成。
论文链接:https://arxiv.org/abs/2401.07519
项目地址:
https://instantid.github.io/
2.PhotoMaker:高效个性化定制人像照片
近年来、文生图技术在根据给定的文本提示合成逼真的人类照片方面已经取得了显著进展。但现有的个性化生成方法无法同时满足高效率、保证身份(ID)保真度以及灵活的文本可控性的要求。
为此、来自南开大学、腾讯公司和东京大学的研究团队提出了一种高效的个性化文本生成图像方法——
PhotoMaker。PhotoMaker 能够将任意数量的输入 ID 图像编码成一个堆叠的 ID 嵌入、以保留 ID 信息。作为一个统一的 ID 表示、这种嵌入不仅能够全面封装相同输入 ID 的特征、还能够容纳不同
ID 的特征以供后续整合。这为更多有趣且具有实际价值的应用提供可能。
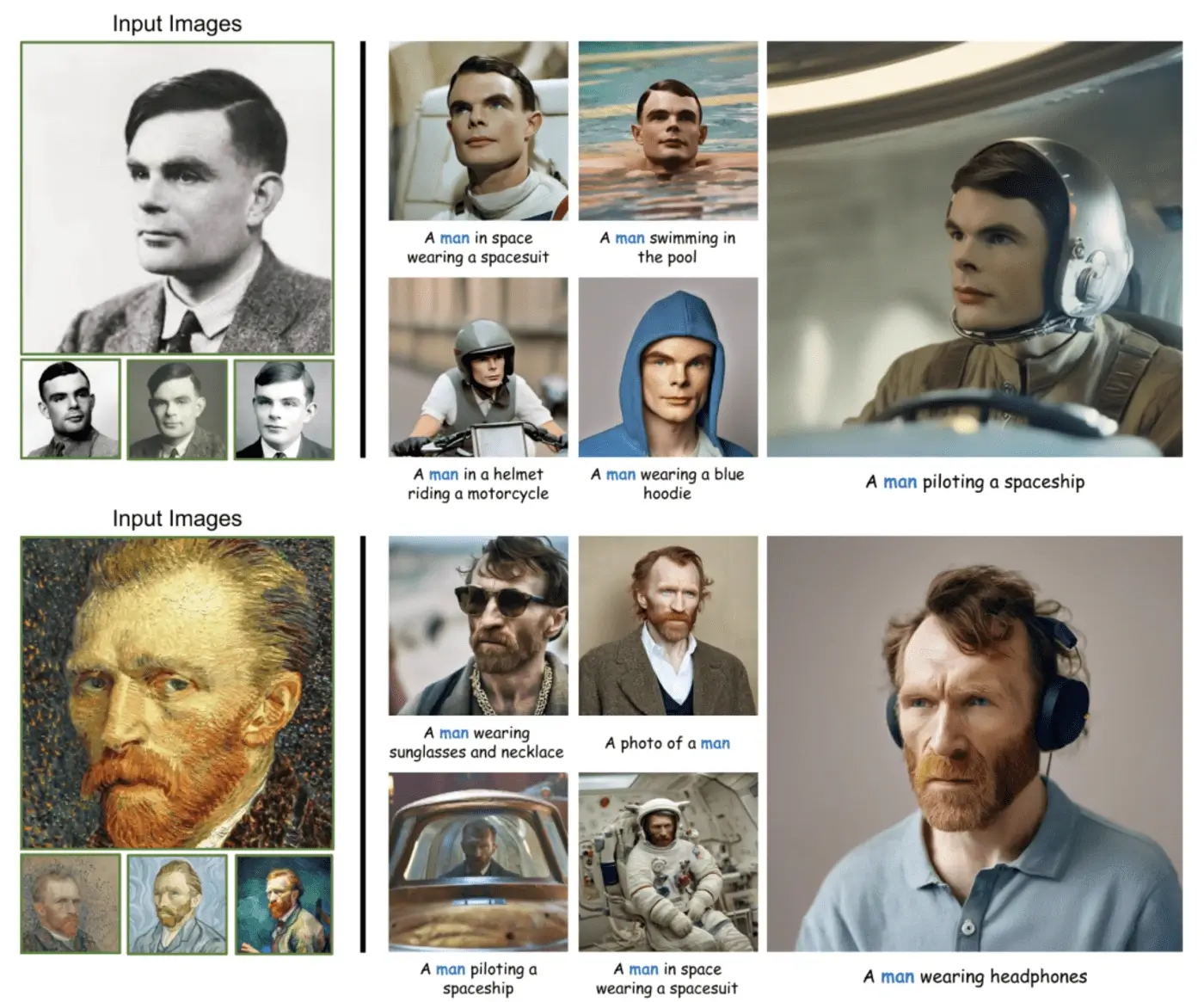
为了推动 PhotoMaker 的训练、研究人员提出了一个面向 ID 的数据构建 pipeline
来收集训练数据。与基于测试时间微调的方法相比、在这一方法构建的数据集的滋养下、PhotoMaker 展示了更好的 ID 保存能力、还提供了显著的速度改进、高质量的生成结果、强大的泛化能力以及广泛的应用范围。
论文链接:https://arxiv.org/abs/2312.04461
项目地址:
https://photo-maker.github.io/
3.ConsiStory:无需额外训练的一致性文生图
文生图模型允许用户通过自然语言指导图像生成过程、将创意灵活性提升到一个新的水平。但使用这些模型在不同的提示中始终如一地描绘同一主题仍具挑战。现有方法通过微调模型来教它描述用户提供的特定主题的新词、或为模型添加图像条件。这些方法需要对每个主题进行长时间的优化或大规模的预训练、同时也很难将生成的图像与文本提示对齐、在描述多个主题时也存在困难
为此、来自英伟达和特拉维夫大学的研究团队及其合作者提出了一种无需训练的方法——ConsiStory、它通过共享预训练模型的内部激活、实现一致的主题生成。

研究团队引入了主题驱动的共享注意力块和基于对应关系的特征注入、以促进图像之间的主题一致性。为了在保持主题一致性的同时鼓励布局多样性、研究团队将 ConsiStory
与一系列基线进行了比较、无需任何优化步骤、ConsiStory 在主题一致性和文本对齐方面实现了 SOTA。ConsiStory 可以自然地扩展到多主题场景、甚至可以实现对常见对象的无训练个性化。
论文链接:https://arxiv.org/abs/2402.03286
项目地址: https://research.nvidia.com/labs
/par/consistory/
4.只需一张图、轻松、快速定制个性化照片
来自香港大学、阿里巴巴和蚂蚁集团的研究团队推出了一种实用工具 FlashFace、用户只需提供一张或几张参考人脸图像和文字提示、就能轻松地即时个性化自己的照片。

FlashFace
有别于现有的人类照片定制方法、具有更高的身份保真度和更好的指令跟随性、这得益于两个微妙的设计。一是该技术将人脸身份编码为一系列特征图、而不是像以前的技术那样编码为一个图像
token、从而使模型能够保留参考人脸的更多细节(如疤痕、纹身和脸型)。二是在文本到图像的生成过程中、FlashFace
引入了一种分离整合策略来平衡文本和图像引导、从而缓解了参考人脸和文本提示之间的冲突(例如、将成人个性化为“儿童”或“老人”)。
大量实验证明了 FlashFace 在各种应用中的有效性、其中包括人像个性化、语言提示下的人脸互换、将虚拟人物变成真人等。
论文链接:https://arxiv.org/abs/2403.17008
项目地址:
https://jshilong.github.io/flashface-page/
5.华为提出 PixArt-Σ:直接生成 4K 分辨率图像
来自华为诺亚方舟实验室、大连理工大学、香港大学和香港科技大学的研究团队提出了一个能够直接生成 4K 分辨率图像的 Diffusion Transformer(DiT)——PixArt-Σ、它与其前身 PixArt-α 相比有了长足的进步、图像的保真度明显提高、并能更好地与文本提示保持一致。

PixArt-Σ 的一个主要特点是其训练效率。利用 PixArt-α
的基础预训练、它通过纳入更高质量的数据、从“弱”基线发展到“强”模型、我们称之为“弱到强训练”过程。PixArt-Σ 的进步体现在两个方面:一是高质量的训练数据:PixArt-Σ
融合了更高质量的图像数据、以及更精确、更详细的图像说明。二是高效 token 压缩、研究团队在 DiT 框架内提出了一种新的注意力模块、可同时压缩键(keys)和值、从而显著提高效率并促进超高分辨率图像的生成。
得益于这些改进、PixArt-Σ 实现了卓越的图像质量和用户提示功能、同时模型大小(0.6B 参数)明显小于现有的文本到图像扩散模型、如 SDXL(2.6B 参数)和 SD Cascade(5.1B
参数)。此外、PixArt-Σ 能够生成 4K 图像、支持制作高分辨率海报和壁纸、有效地促进了电影和游戏等行业高质量视觉内容的生产。
论文链接:https://arxiv.org/abs/2403.04692
项目地址: https://pixart-alpha.github.io/PixArt-sigma-project/
6.CogView3:通过 Relay Diffusion 实现更精细、更快速的“文生图”
文生图系统的最新进展主要是由扩散模型推动的。然而、单级文本到图像扩散模型在计算效率和图像细节细化方面仍面临挑战。为了解决这个问题、来自清华大学和智谱AI
的研究团队提出了 CogView3——一个能提高文本到图像扩散性能的创新级联框架。
据介绍、CogView3 是第一个在文本到图像生成领域实现 relay diffusion
的模型、它通过首先创建低分辨率图像、然后应用基于中继(relay-based)的超分辨率来执行任务。这种方法不仅能产生有竞争力的文本到图像输出、还能大大降低训练和推理成本。

实验结果表明、在人类评估中、CogView3 比目前最先进的开源文本到图像扩散模型 SDXL 高出 77.0%、而所需的推理时间仅为后者的
1/2。经过提炼(distilled)的 CogView3 变体性能与 SDXL 相当、而推理时间仅为后者的 1/10。
论文链接:https://arxiv.org/abs/2403.05121
GitHub 地址:
https://github.com/THUDM/
CogView3
7.SPRIGHT:提高“文生图”模型的空间一致性
无法始终如一地生成忠实于文本提示中指定的空间关系的图像、是当前文本到图像(T2I)模型的主要缺陷之一。来自亚利桑那州立大学、Intel Labs
的研究团队及其合作者、对这一局限性进行了全面的研究、同时还开发了实现 SOTA 的数据集和方法。
无法始终如一地生成忠实于文本提示中指定的空间关系的图像、是当前文本到图像(T2I)模型的主要缺陷之一。来自亚利桑那州立大学、Intel Labs 的研究团队及其合作者、对这一局限性进行了全面的研究、同时还开发了实现
SOTA 的数据集和方法。

此外、他们发现在包含大量物体的图像上进行训练可大幅提高空间一致性。值得注意的是、通过在小于 500 张图像上进行微调、他们在 T2I-CompBench 上达到了
SOTA、空间分数为 0.2133。
论文链接:https://arxiv.org/abs/2404.01197
项目地址:
https://spright-t2i.github.io/
8.RLCM:通过强化学习微调一致性模型
强化学习(RL)通过直接优化获取图像质量、美学和指令跟随能力的奖励、改进了扩散模型的引导图像生成。然而、由此产生的生成策略继承了扩散模型的迭代采样过程、导致生成速度缓慢。为了克服这一局限性、一致性模型提出学习一类新的生成模型、直接将噪声映射到数据、从而产生一种只需一次采样迭代就能生成图像的模型。
在这项工作中、为了优化文本到图像生成模型从而获得特定任务奖励、并实现快速训练和推理、来自康奈尔大学的研究团队提出了一种通过 RL 对一致性模型进行微调的框架——
RLCM、其将一致性模型的迭代推理过程构建为一个 RL 过程。RLCM 在文本到图像生成能力方面改进了 RL 微调扩散模型、并在推理过程中以计算量换取样本质量

实验表明、RLCM 可以调整文本到图像的一致性模型、从而适应那些难以通过提示来表达的目标(如图像压缩性)和那些来自人类反馈的目标(如审美质量)。与 RL
微调扩散模型相比、RLCM 的训练速度明显更快、提高了在奖励目标下测量的生成质量、并加快了推理过程、只需两个推理步骤就能生成高质量图像。
论文链接:https://arxiv.org/abs/2404.03673
项目地址:
hhttps://rlcm.owenoertell.com/
9.清华、Meta 提出文生图定制生成新方法 MultiBooth
来自清华大学和 Meta 的研究团队提出了一种用于从文生图的多概念定制的新型高效技术—— MultiBooth。尽管定制生成方法取得了长足的进步、特别是随着扩散模型的快速发展、但由于概念保真度低和推理成本高、现有方法在处理多概念场景时依然困难。
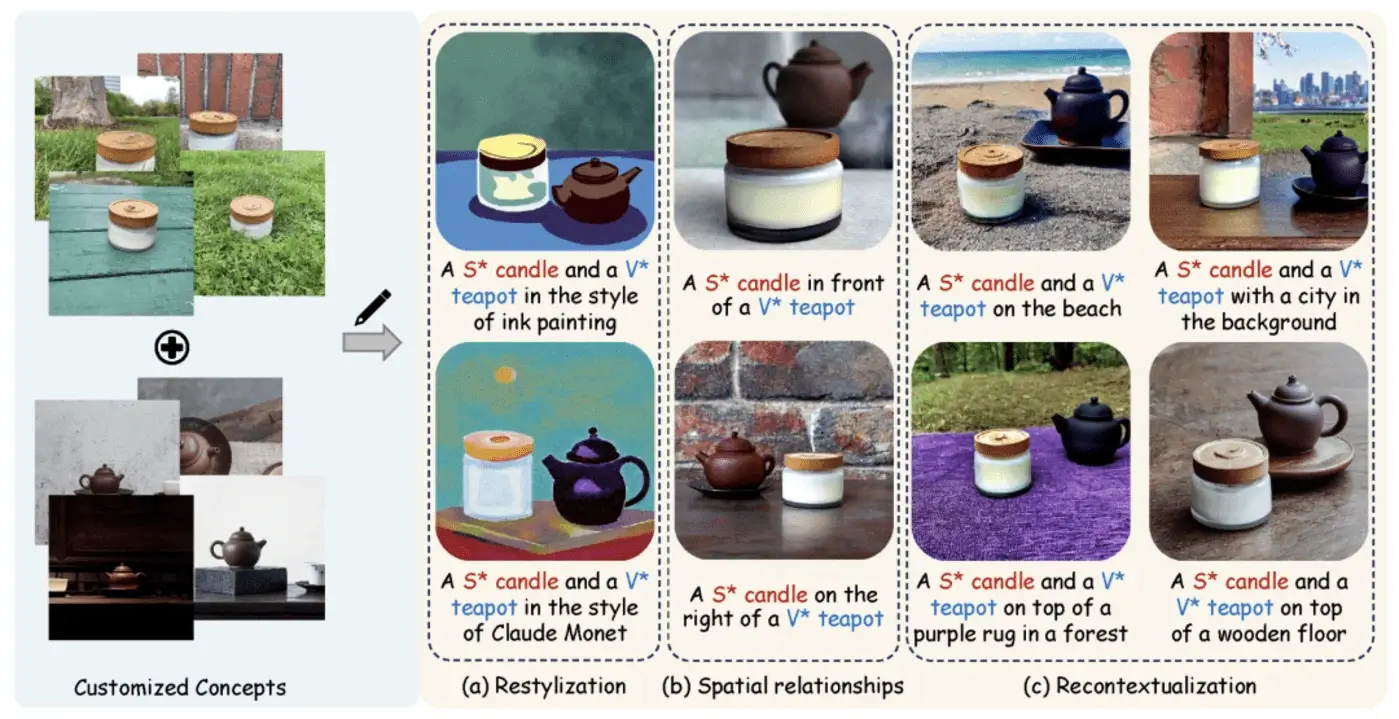
为了解决这些问题、MultiBooth
将多概念生成过程分为两个阶段:单一概念学习阶段和多概念整合阶段。在单概念学习阶段、他们采用多模态图像编码器和高效的概念编码技术、为每个概念学习一个简明且具有辨别力的表征;在多概念整合阶段、他们使用边界框来定义交叉注意图中每个概念的生成区域。这种方法可以在指定区域内创建单个概念、从而促进多概念图像的形成。
这一策略不仅提高了概念的保真度、还降低了额外的推理成本。在定性和定量评估中、MultiBooth 都超越了各种基线、展示了其卓越的性能和计算效率。
论文链接:https://arxiv.org/abs/2404.14239
项目地址:
https://multibooth.github.io/
10.清华、智谱团队推出无限超分辨率模型 Inf-DiT
近年来、扩散模型在图像生成方面表现出了卓越的性能。然而、由于在生成超高分辨率图像(如 4096*4096)的过程中内存会二次增加、生成图像的分辨率往往被限制在
1024*1024。
在这项工作中、来自清华和智谱AI 的研究团队提出了一种单向块(unidirectional block)注意力机制、其可以在推理过程中自适应地调整内存开销、并处理全局依赖关系。在此模块的基础上、他们采用 DiT
结构进行上采样、并开发了一种无限超分辨率模型、能够对各种形状和分辨率的图像进行上采样。

综合实验表明、这一模型在生成超高分辨率图像方面达到了机器和人工评估的 SOTA 性能。与常用的 UNet 结构相比、这一模型在生成 4096*4096 图像时可以节省
5 倍以上的内存。
论文链接:https://arxiv.org/abs/2405.04312
ttps://arxiv.org/abs/2410.10629 https://github.com/THUDM/Inf-DiT
11.何恺明新作:无需矢量量化的自回归图像生成
传统观点认为、用于图像生成的自回归模型通常都伴随着向量量化的 token。
麻省理工学院计算机科学与人工智能实验室(MIT CSAIL)何恺明团队与来自 Google DeepMind 和清华大学的合作者发现、虽然离散值空间有助于表示分类分布、但它并不是自回归建模的必要条件。
在这项工作中、他们建议使用扩散程序对每个 token 的概率分布进行建模、这样便可以在连续值空间中应用自回归模型。他们没有使用分类交叉熵损失、而是定义了一个扩散损失函数来为每个 token
概率建模。这种方法无需使用离散值
tokenizers、他们评估了其在各种情况下的有效性、包括标准自回归模型和广义掩码自回归(MAR)变体。通过去除矢量量化、他们提出的图像生成器在具有序列建模的速度优势的同时、还取得了很好的效果。

他们希望这项工作能推动自回归生成技术在其他连续值领域和应用中的应用。
论文链接:https://arxiv.org/abs/2406.11838
GitHub 地址:
https://github.com/LTH14/mar
12.小红书推出 StoryMaker:实现“文生图”的特征整体一致
无需额外微调(Tuning-free)的个性化图像生成方法在保持面部一致性方面取得了巨大成功。然而、在有多个角色的场景中、缺乏整体一致性阻碍了这些方法创造连贯叙事的能力。
在这项工作中、小红书团队推出了一种个性化解决方案——
StoryMaker、它不仅能保持面部的一致性、还能保持服装、发型和身体的一致性、从而通过一系列图像促进故事的创作。

StoryMaker
融合了基于面部身份的条件和裁剪后的人物图像。具体来说、他们使用位置感知感知器重采样器(PPR)将面部身份信息与裁剪后的人物图像整合在一起、从而获得鲜明的人物特征。为了防止多个人物和背景混杂在一起、他们使用带有分割掩码的
MSE 损失分别限制不同人物和背景的交叉注意力影响区域。此外、他们以姿势为条件训练生成网络、从而促进与姿势的解耦。他们还采用了 LoRA 来提高保真度和质量
论文链接:https://arxiv.org/abs/2409.12576
GitHub 地址:
https://github.com/RedAIGC/
StoryMaker
13.英伟达文生图框架 SANA :高效生成高分辨率图像
英伟达研究团队及其合作者提出了一个文生图框架 Sana、它可以高效生成分辨率高达 4096×4096 的图像。Sana 可以在笔记本电脑 GPU 上以极快的速度合成高分辨率、高质量的图像、并具有很强的文生图对齐能力。

核心设计包括:(1)深度压缩自动编码器:与传统的自动编码器只能压缩图像 8 倍不同、他们训练的自动编码器可以压缩图像 32 倍、有效减少了潜在 token
的数量。(2)线性 DiT:他们用线性注意力取代了 DiT 中的所有 vanilla attention、在不牺牲质量的情况下、线性注意力在高分辨率下效率更高。(3)纯解码器文本编码器:他们用现代纯解码器小型 LLM
代替 T5 作为文本编码器、并设计了复杂的人机指令与上下文学习、以增强图像与文本的对齐。(4)高效的训练和采样:他们提出了 Flow-DPM-Solver 以减少采样步骤、并通过高效的标题标注和选择来加速收敛。
Sana-0.6B 与现代巨型扩散模型(如 Flux-12B)相比具有很强的竞争力、体积小了 20 倍、测量吞吐量快了 100 多倍。此外、Sana-0.6B 可在 16GB 笔记本电脑 GPU 上部署、生成
1024×1024 分辨率图像的时间不到 1 秒。Sana 能够以低成本创建内容。
论文链接:https://arxiv.org/abs/2410.10629
项目地址:
https://nvlabs.github.io/Sana/
14.Kandinsky-3:一种新型文生图扩散模型
文生图(T2I)扩散模型是引入图像处理方法的常用模型、如编辑、图像融合、图像修复等。同时、图生视频(I2V)和文生视频(T2V)模型也建立在 T2I 模型之上。来自 SberAI 的研究团队及其合作者推出了一种基于潜在扩散的新型 T2I 模型——Kandinsky 3、其具有很高的质量和逼真度。

新架构的主要特点是简单高效、可适应多种类型的生成任务。他们针对各种应用扩展了基础 T2I
模型、并创建了一个多功能生成系统、其中包括文本引导的补画/扩画、图像融合、文本图像融合、图像变化生成、I2V 和 T2V 生成。他们还提出了经过提炼的 T2I 模型版本、在不降低图像质量的情况下、在反向流程的 4
个步骤中对推理进行评估、速度比基本模型快 3 倍。他们部署了一个用户友好型演示系统、所有功能都可以在公共领域进行测试。
此外、他们还发布了 Kandinsky 3 和扩展模型的源代码和检查点。人工评估结果显示、Kandinsky 3 是开源生成系统中质量得分最高的系统之一。
论文链接:https://arxiv.org/abs/2410.21061
GitHub 地址:
https://github.com/ai-forever/Kandinsky-3
15.FlipSketch:将静态图纸变为文本引导的草图动画
草图动画为视觉叙事提供了一个强大的媒介、从简单的翻书涂鸦到专业的工作室制作、无所不包。传统的动画制作需要熟练的艺术家团队来绘制关键帧和中间帧、而现有的自动化尝试仍然需要通过精确的运动路径或关键帧规范来完成大量的艺术工作。
在这项工作中、萨里大学 SketchX 团队推出的 FlipSketch 系统能让你重拾翻书动画的魅力——只需画出你的想法、并描述你希望它如何运动即可。
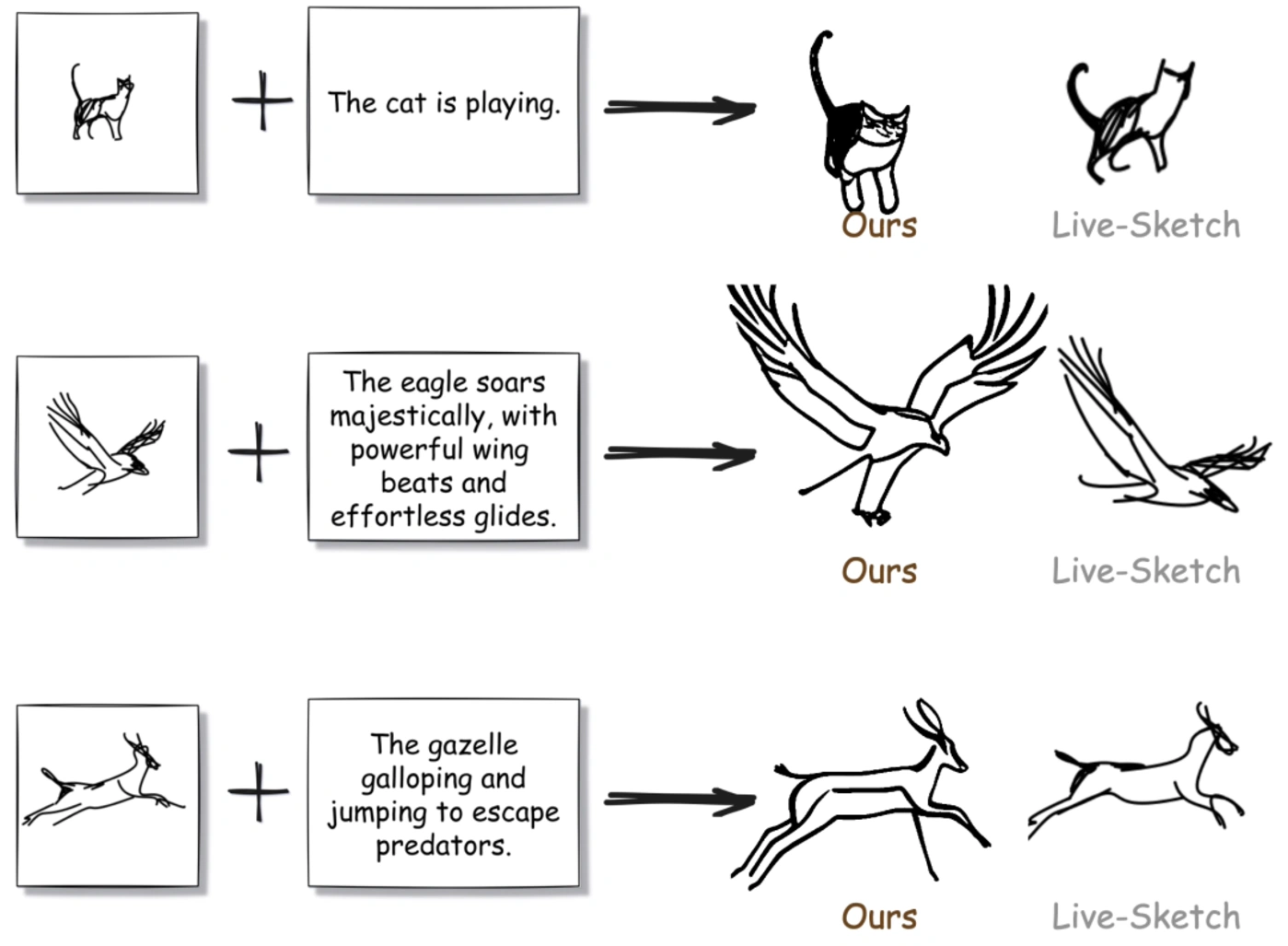
这一方法利用从文本到视频扩散模型的运动先验、通过三个关键创新将其调整为生成草图动画:(1)微调草图风格的帧生成、(2)参考帧机制、通过噪声细化保持输入草图的视觉完整性、(3)双注意力合成、在不失去视觉一致性的情况下实现流畅运动。与受限的矢量动画不同、他们的光栅框架支持动态草图变换、捕捉到了传统动画的自由表现力。
论文链接:https://arxiv.org/abs/2411.10818
项目地址: https://hmrishavbandy.github.io/
flipsketch-web/
16.OneDiffusion:一个扩散生成所有
在这项工作中、来自 AI2 和加州大学尔湾分校的研究团队推出了一种通用的大规模扩散模型 OneDiffusion、其可以无缝支持不同任务中的双向图像合成和理解、能够根据文本、深度、姿态、布局和语义图等输入条件生成图像、同时还能处理图像去模糊、放大以及深度估计和分割等反向处理任务。

此外、OneDiffusion
还可以生成多视图、进行相机姿态估计、并利用连续图像输入进行即时个性化处理。该模型在训练过程中将所有任务都视为具有不同噪声尺度的帧序列、允许任何帧在推理时充当条件图像。这一统一训练框架无需专用架构、支持可扩展的多任务训练、并可以适应任何分辨率、从而增强了通用性和可扩展性。
实验结果表明、尽管训练数据集相对较小、但在文本到图像、多视图生成、身份保护、深度估计和相机姿态估计等生成和预测任务中、这一训练框架都具有很强的竞争力。
论文链接:https://arxiv.org/abs/2411.16318
GitHub 地址:
https://github.com/lehduong/
OneDiffusion
17.北大团队提出「自定义漫画生成」框架 DiffSensei
故事可视化是从文本描述创建视觉叙事的任务、文本到图像的生成模型已经取得了进展。然而、这些模型往往缺乏对角色外观和互动的有效控制、尤其是在多角色场景中。
为了解决这些局限性、来自北京大学的研究团队及其合作者提出了一项新任务:自定义漫画生成、并提出了 DiffSensei、这是一个专门用于生成动态多角色控制漫画的创新框架。DiffSensei
集成了基于扩散的图像生成器和多模态大语言模型(MLLM)、后者是一种文本兼容身份适配器。他们的方法采用了掩码交叉注意力技术、可无缝整合字符特征、从而在不直接传输像素的情况下实现精确的布局控制。此外、基于 MLLM
的适配器还能调整角色特征、使其与特定面板的文本线索保持一致、从而灵活调整角色的表情、姿势和动作。

他们还提出了 MangaZero、这是一个专为这项任务定制的大型数据集、包含 43264 页漫画和 427147
个注释面板、支持跨连续帧的各种角色互动和动作的可视化。广泛的实验证明、DiffSensei 的性能优于现有模型、通过实现文本适应性角色定制、标志着漫画生成技术的重大进步。
论文链接:https://arxiv.org/abs/2412.07589
项目地址: https://jianzongwu.github.io/
projects/diffsensei/
18.SnapGen:极小、快速的高分辨率“文生图”
现有的文本到图像(T2I)扩散模型面临几个限制、包括模型规模大、运行速度慢以及在移动设备上生成的图像质量低。来自 Snap 的研究团队及其合作者旨在通过开发一种极小且快速的 T2I 模型、在移动平台上生成高分辨率和高质量的图像、从而应对所有这些挑战。

为实现这一目标、他们提出了几种技术。首先、他们系统地检查了网络架构的设计选择、以减少模型参数和延迟、同时确保高质量的生成。其次、为了进一步提高生成质量、他们从一个更大的模型中采用了跨架构知识提炼、使用多层次方法指导他们的模型从头开始训练。第三、他们通过将对抗指导与知识提炼相结合、实现了几步生成。
他们的模型 SnapGen 在移动设备上生成 1024x1024 px 图像的时间仅为 1.4 秒。在 ImageNet-1K 上、模型只需 372M 参数就能生成 256x256 px 的图像、FID
达到 2.06。在 T2I 基准(即 GenEval 和 DPG-Bench)上、他们的模型仅有 379M 个参数、以明显更小的规模(例如、比 SDXL 小 7 倍、比 IF-XL 小 14
倍)超越了拥有数十亿个参数的大模型。
论文链接:https://arxiv.org/abs/2412.09619
项目地址:
https://snap-research.github.io/snapgen/
完整版:
https://oosdj1g7qa.feishu.cn/docx/
YXfLdKN6po7UPsxC3Eycoboondg
